A customer receives the message shown below in their EMS logs.
Tue Jun 27 18:34:18 CEST
[netapp-ct1: cp_worker: wafl.cp.toolong:error]: Aggregate AG1_NTAP_PROD experienced a long CP.
Tue Jun 27 18:37:10 CEST
Which two data sources do you use to explain this message? (Choose two.)
You are working on a fabric MetroCluster. After a site failure, the plex starts to resync automatically to the aggregate mirror of Aggr1. The plex now shows a status of resyncing. During this process, you experience a slow resync of the SyncMirror plex.
In this scenario, how do you solve the problem?
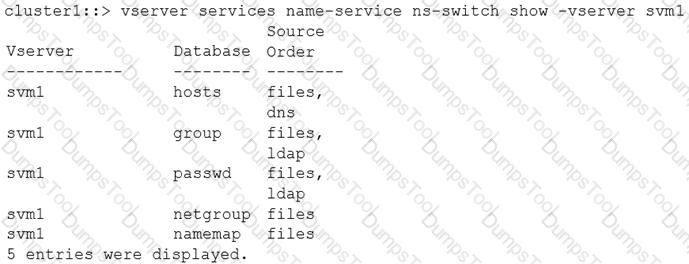
Referring to the exhibit, the UNIX user "prof1" will be looked up in which source first?

TESTED 04 Apr 2025