When using the Platform Navigator, what permission is required to add users and user groups?
root
Super-user
Administrator
User
In IBM Cloud Pak for Integration (CP4I) v2021.2, the Platform Navigator is the central UI for managing integration capabilities, including user and access control. To add users and user groups, the required permission level is Administrator.
User Management Capabilities:
The Administrator role in Platform Navigator has full access to user and group management functions, including:
Adding new users
Assigning roles
Managing access policies
RBAC (Role-Based Access Control) Enforcement:
CP4I enforces RBAC to restrict actions based on roles.
Only Administrators can modify user access, ensuring security compliance.
Access Control via OpenShift and IAM Integration:
User management in CP4I integrates with IBM Cloud IAM or OpenShift User Management.
The Administrator role ensures correct permissions for authentication and authorization.
Why is "Administrator" the Correct Answer?
Why Not the Other Options?Option
Reason for Exclusion
A. root
"root" is a Linux system user and not a role in Platform Navigator. CP4I does not grant UI-based root access.
B. Super-user
No predefined "Super-user" role exists in CP4I. If referring to an elevated user, it still does not match the Administrator role in Platform Navigator.
D. User
Regular "User" roles have view-only or limited permissions and cannot manage users or groups.
Thus, the Administrator role is the correct choice for adding users and user groups in Platform Navigator.
IBM Cloud Pak for Integration - Platform Navigator Overview
Managing Users in Platform Navigator
Role-Based Access Control in CP4I
OpenShift User Management and Authentication
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which statement is true about the removal of individual subsystems of API Connect on OpenShift or Cloud Pak for Integration?
They can be deleted regardless of the deployment methods.
They can be deleted if API Connect was deployed using a single top level CR.
They cannot be deleted if API Connect was deployed using a single top level CR.
They cannot be deleted if API Connect was deployed using a single top level CRM.
In IBM Cloud Pak for Integration (CP4I) v2021.2, when deploying API Connect on OpenShift or within the Cloud Pak for Integration framework, there are different deployment methods:
Single Top-Level Custom Resource (CR) – This method deploys all API Connect subsystems as a single unit, meaning they are managed together. Removing individual subsystems is not supported when using this deployment method. If you need to remove a subsystem, you must delete the entire API Connect instance.
Multiple Independent Custom Resources (CRs) – This method allows more granular control, enabling the deletion of individual subsystems without affecting the entire deployment.
Since the question specifically asks about API Connect deployed using a single top-level CR, it is not possible to delete individual subsystems. The entire deployment must be deleted and reconfigured if changes are required.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM API Connect v10 Documentation: IBM Docs - API Connect on OpenShift
IBM Cloud Pak for Integration Knowledge Center: IBM CP4I Documentation
API Connect Deployment Guide: Managing API Connect Subsystems
What is the outcome when the API Connect operator is installed at the cluster scope?
Automatic updates will be restricted by the approval strategy.
API Connect services will be deployed in the default namespace.
The operator installs in a production deployment profile.
The entire cluster effectively behaves as one large tenant.
When the API Connect operator is installed at the cluster scope, it means that the operator has permissions and visibility across the entire Kubernetes or OpenShift cluster, rather than being limited to a single namespace. This setup allows multiple namespaces to utilize the API Connect resources, effectively making the entire cluster behave as one large tenant.
Cluster-wide installation enables shared services across multiple namespaces, ensuring that API management is centralized.
Multi-tenancy behavior occurs because all API Connect components, such as the Gateway, Analytics, and Portal, can serve multiple teams or applications within the cluster.
Operator Lifecycle Manager (OLM) governs how the API Connect operator is deployed and managed across namespaces, reinforcing the unified behavior across the cluster.
IBM API Connect Operator Documentation
IBM Cloud Pak for Integration - Installing API Connect
IBM Redbook - Cloud Pak for Integration Architecture Guide
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which storage type is supported with the App Connect Enterprise (ACE) Dash-board instance?
Ephemeral storage
Flash storage
File storage
Raw block storage
In IBM Cloud Pak for Integration (CP4I) v2021.2, App Connect Enterprise (ACE) Dashboard requires persistent storage to maintain configurations, logs, and runtime data. The supported storage type for the ACE Dashboard instance is file storage because:
It supports ReadWriteMany (RWX) access mode, allowing multiple pods to access shared data.
It ensures data persistence across restarts and upgrades, which is essential for managing ACE integrations.
It is compatible with NFS, IBM Spectrum Scale, and OpenShift Container Storage (OCS), all of which provide file system-based storage.
A. Ephemeral storage – Incorrect
Ephemeral storage is temporary and data is lost when the pod restarts or gets rescheduled.
ACE Dashboard needs persistent storage to retain configuration and logs.
B. Flash storage – Incorrect
Flash storage refers to SSD-based storage and is not specifically required for the ACE Dashboard.
While flash storage can be used for better performance, ACE requires file-based persistence, which is different from flash storage.
D. Raw block storage – Incorrect
Block storage is low-level storage that is used for databases and applications requiring high-performance IOPS.
ACE Dashboard needs a shared file system, which block storage does not provide.
Why the other options are incorrect:
IBM App Connect Enterprise (ACE) Storage Requirements
IBM Cloud Pak for Integration Persistent Storage Guide
OpenShift Persistent Volume Types
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which two authentication types are supported for single sign-on in Founda-tional Services?
Basic Authentication
OpenShift authentication
PublicKey
Enterprise SAML
Local User Registry
In IBM Cloud Pak for Integration (CP4I) v2021.2, Foundational Services provide authentication and access control mechanisms, including Single Sign-On (SSO) integration. The two supported authentication types for SSO are:
OpenShift Authentication
IBM Cloud Pak for Integration leverages OpenShift authentication to integrate with existing identity providers.
OpenShift authentication supports OAuth-based authentication, allowing users to sign in using an OpenShift identity provider, such as LDAP, OIDC, or SAML.
This method enables seamless user access without requiring additional login credentials.
Enterprise SAML (Security Assertion Markup Language)
SAML authentication allows integration with enterprise identity providers (IdPs) such as IBM Security Verify, Okta, Microsoft Active Directory Federation Services (ADFS), and other SAML 2.0-compatible IdPs.
It provides federated identity management for SSO across enterprise applications, ensuring secure access to Cloud Pak services.
A. Basic Authentication – Incorrect
Basic authentication (username and password) is not used for Single Sign-On (SSO). SSO mechanisms require identity federation through OpenID Connect (OIDC) or SAML.
C. PublicKey – Incorrect
PublicKey authentication (such as SSH key-based authentication) is used for system-level access, not for SSO in Foundational Services.
E. Local User Registry – Incorrect
While local user registries can store credentials, they do not provide SSO capabilities. SSO requires federated identity providers like OpenShift authentication or SAML-based IdPs.
Why the other options are incorrect:
IBM Cloud Pak Foundational Services Authentication Guide
OpenShift Authentication and Identity Providers
IBM Cloud Pak for Integration SSO Configuration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What is the minimum Red Hat OpenShift version for Cloud Pak for Integration V2021.2?
4.7.4
4.6.8
4.7.4
4.6.2
IBM Cloud Pak for Integration (CP4I) v2021.2 is designed to run on Red Hat OpenShift Container Platform (OCP). Each version of CP4I has a minimum required OpenShift version to ensure compatibility, performance, and security.
For Cloud Pak for Integration v2021.2, the minimum required OpenShift version is 4.7.4.
Compatibility: CP4I components, including IBM MQ, API Connect, App Connect, and Event Streams, require specific OpenShift versions to function properly.
Security & Stability: Newer OpenShift versions include critical security updates and performance improvements essential for enterprise deployments.
Operator Lifecycle Management (OLM): CP4I uses OpenShift Operators, and the correct OpenShift version ensures proper installation and lifecycle management.
Minimum required OpenShift version: 4.7.4
Recommended OpenShift version: 4.8 or later
Key Considerations for OpenShift Version Requirements:IBM’s Official Minimum OpenShift Version Requirements for CP4I v2021.2:
IBM officially requires at least OpenShift 4.7.4 for deploying CP4I v2021.2.
OpenShift 4.6.x versions are not supported for CP4I v2021.2.
OpenShift 4.7.4 is the first fully supported version that meets IBM's compatibility requirements.
Why Answer A (4.7.4) is Correct?
B. 4.6.8 → Incorrect
OpenShift 4.6.x is not supported for CP4I v2021.2.
IBM Cloud Pak for Integration v2021.1 supported OpenShift 4.6, but v2021.2 requires 4.7.4 or later.
C. 4.7.4 → Correct
This is the minimum required OpenShift version for CP4I v2021.2.
D. 4.6.2 → Incorrect
OpenShift 4.6.2 is outdated and does not meet the minimum version requirement for CP4I v2021.2.
Explanation of Incorrect Answers:
IBM Cloud Pak for Integration v2021.2 System Requirements
Red Hat OpenShift Version Support Matrix
IBM Cloud Pak for Integration OpenShift Deployment Guide
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which command shows the current cluster version and available updates?
update
adm upgrade
adm update
upgrade
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on OpenShift, administrators often need to check the current cluster version and available updates before performing an upgrade.
The correct command to display the current OpenShift cluster version and check for available updates is:
oc adm upgrade
This command provides information about:
The current OpenShift cluster version.
Whether a newer version is available for upgrade.
The channel and upgrade path.
A. update – Incorrect
There is no oc update or update command in OpenShift CLI for checking cluster versions.
C. adm update – Incorrect
oc adm update is not a valid command in OpenShift. The correct subcommand is adm upgrade.
D. upgrade – Incorrect
oc upgrade is not a valid OpenShift CLI command. The correct syntax requires adm upgrade.
Why the other options are incorrect:
Example Output of oc adm upgrade:$ oc adm upgrade
Cluster version is 4.10.16
Updates available:
Version 4.11.0
Version 4.11.1
OpenShift Cluster Upgrade Documentation
IBM Cloud Pak for Integration OpenShift Upgrade Guide
Red Hat OpenShift CLI Reference
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which statement is true about the Authentication URL user registry in API Connect?
It authenticates Developer Portal sites.
It authenticates users defined in a provider organization.
It authenticates Cloud Manager users.
It authenticates users by referencing a custom identity provider.
In IBM API Connect, an Authentication URL user registry is a type of user registry that allows authentication by delegating user verification to an external identity provider. This is typically used when API Connect needs to integrate with custom authentication mechanisms, such as OAuth, OpenID Connect, or SAML-based identity providers.
When configured, API Connect does not store user credentials locally. Instead, it redirects authentication requests to the specified external authentication URL, and if the response is valid, the user is authenticated.
The Authentication URL user registry is specifically designed to reference an external custom identity provider.
This enables API Connect to integrate with external authentication systems like LDAP, Active Directory, OAuth, and OpenID Connect.
It is commonly used for single sign-on (SSO) and enterprise authentication strategies.
Why Answer D is Correct:
A. It authenticates Developer Portal sites. → Incorrect
The Developer Portal uses its own authentication mechanisms, such as LDAP, local user registries, and external identity providers, but the Authentication URL user registry does not authenticate Developer Portal users directly.
B. It authenticates users defined in a provider organization. → Incorrect
Users in a provider organization (such as API providers and administrators) are typically authenticated using Cloud Manager or an LDAP-based user registry, not via an Authentication URL user registry.
C. It authenticates Cloud Manager users. → Incorrect
Cloud Manager users are typically authenticated via LDAP or API Connect’s built-in user registry.
The Authentication URL user registry is not responsible for Cloud Manager authentication.
Explanation of Incorrect Answers:
IBM API Connect User Registry Types
IBM API Connect Authentication and User Management
IBM Cloud Pak for Integration Documentation
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
https://www.ibm.com/docs/SSMNED_v10/com.ibm.apic.cmc.doc/capic_cmc_registries_concepts.html
Select all that apply
What is the correct order of the Operations Dashboard upgrade?


Upgrading the operator
If asked, approve the install plan
Upgrading the operand
Upgrading the traced integration capabilities
1️⃣ Upgrade operator using Operator Lifecycle Manager.
The Operator Lifecycle Manager (OLM) manages the upgrade of the Operations Dashboard operator in OpenShift.
This ensures that the latest version is available for managing operands.
2️⃣ If asked, approve the Install Plan.
Some installations require manual approval of the Install Plan to proceed with the operator upgrade.
If configured for automatic updates, this step may not be required.
3️⃣ Upgrade the operand.
Once the operator is upgraded, the operand (Operations Dashboard instance) needs to be updated to the latest version.
This step ensures that the upgraded operator manages the most recent operand version.
4️⃣ Upgrade traced integration capabilities.
Finally, upgrade any traced integration capabilities that depend on the Operations Dashboard.
This step ensures compatibility and full functionality with the updated components.
In IBM Cloud Pak for Integration (CP4I) v2021.2, the Operations Dashboard provides tracing and monitoring for integration capabilities. The correct upgrade sequence ensures a smooth transition with minimal downtime:
Upgrade the Operator using OLM – The Operator manages operands and must be upgraded first.
Approve the Install Plan (if required) – Some operator updates require manual approval before proceeding.
Upgrade the Operand – The actual Operations Dashboard component is upgraded after the operator.
Upgrade Traced Integration Capabilities – Ensures all monitored services are compatible with the new Operations Dashboard version.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Upgrading Operators using Operator Lifecycle Manager (OLM)
IBM Cloud Pak for Integration Operations Dashboard
Best Practices for Upgrading CP4I Components
Which OpenShift component controls the placement of workloads on nodes for Cloud Pak for Integration deployments?
API Server
Controller Manager
Etcd
Scheduler
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, the component responsible for determining the placement of workloads (pods) on worker nodes is the Scheduler.
API Server (Option A): The API Server is the front-end of the OpenShift and Kubernetes control plane, handling REST API requests, authentication, and cluster state updates. However, it does not decide where workloads should be placed.
Controller Manager (Option B): The Controller Manager ensures the desired state of the system by managing controllers (e.g., ReplicationController, NodeController). It does not handle pod placement.
Etcd (Option C): Etcd is the distributed key-value store used by OpenShift and Kubernetes to store cluster state data. It plays no role in scheduling workloads.
Scheduler (Option D - Correct Answer): The Scheduler is responsible for selecting the most suitable node to run a newly created pod based on resource availability, affinity/anti-affinity rules, and other constraints.
When a new pod is created, it initially has no assigned node.
The Scheduler evaluates all worker nodes and assigns the pod to the most appropriate node, ensuring balanced resource utilization and policy compliance.
In CP4I, efficient workload placement is crucial for maintaining performance and resilience, and the Scheduler ensures that workloads are optimally distributed across the cluster.
Explanation of OpenShift Components:Why the Scheduler is Correct?IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM CP4I Documentation – Deploying on OpenShift
Red Hat OpenShift Documentation – Understanding the Scheduler
Kubernetes Documentation – Scheduler
What are two ways an Aspera HSTS Instance can be created?
Foundational Services Dashboard
OpenShift console
Platform Navigator
IBM Aspera HSTS Installer
Terraform
IBM Aspera High-Speed Transfer Server (HSTS) is a key component of IBM Cloud Pak for Integration (CP4I) that enables secure, high-speed data transfers. There are two primary methods to create an Aspera HSTS instance in CP4I v2021.2:
OpenShift Console (Option B - Correct):
Aspera HSTS can be deployed within an OpenShift cluster using the OpenShift Console.
Administrators can deploy Aspera HSTS by creating an instance from the IBM Aspera HSTS operator, which is available through the OpenShift OperatorHub.
The deployment is managed using Kubernetes custom resources (CRs) and YAML configurations.
IBM Aspera HSTS Installer (Option D - Correct):
IBM provides an installer for setting up an Aspera HSTS instance on supported platforms.
This installer automates the process of configuring the required services and dependencies.
It is commonly used for standalone or non-OpenShift deployments.
Analysis of Other Options:
Option A (Foundational Services Dashboard) - Incorrect:
The Foundational Services Dashboard is used for managing IBM Cloud Pak foundational services like identity and access management but does not provide direct deployment of Aspera HSTS.
Option C (Platform Navigator) - Incorrect:
Platform Navigator is used to manage cloud-native integrations, but it does not directly create Aspera HSTS instances. Instead, it can be used to access and manage the Aspera HSTS services after deployment.
Option E (Terraform) - Incorrect:
While Terraform can be used to automate infrastructure provisioning, IBM does not provide an official Terraform module for directly creating Aspera HSTS instances in CP4I v2021.2.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Documentation: Deploying Aspera HSTS on OpenShift
IBM Aspera Knowledge Center: Aspera HSTS Installation Guide
IBM Redbooks: IBM Cloud Pak for Integration Deployment Guide
When considering storage for a highly available single-resilient queue manager, which statement is true?
A shared file system must be used that provides data write integrity, granting exclusive access to file and release locks on failure.
To tolerate an outage of an entire availability zone, cloud storage which replicates across two other zones must be used.
Persistent volumes are not supported for a resilient queue manager.
A single resilient queue manager takes much longer to recover than a multi instance queue manager
In IBM Cloud Pak for Integration (CP4I) v2021.2, when deploying a highly available single-resilient queue manager, storage considerations are crucial to ensuring fault tolerance and failover capability.
A single-resilient queue manager uses a shared file system that allows different queue manager instances to access the same data, enabling failover to another node in the event of failure. The key requirement is data write integrity, ensuring that only one instance has access at a time and that locks are properly released in case of a node failure.
Option A is correct: A shared file system must support data consistency and failover mechanisms to ensure that only one instance writes to the queue manager logs and data at any time. If the active instance fails, another instance can take over using the same storage.
Option B is incorrect: While cloud storage replication across availability zones is useful, it does not replace the need for a proper shared file system with write integrity.
Option C is incorrect: Persistent volumes are supported for resilient queue managers when deployed in Kubernetes environments like OpenShift, as long as they meet the required file system properties.
Option D is incorrect: A single resilient queue manager can recover quickly by failing over to a standby node, often faster than a multi-instance queue manager, which requires additional failover processes.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM MQ High Availability Documentation
IBM Cloud Pak for Integration Storage Considerations
IBM MQ Resiliency and Disaster Recovery Guide
Which diagnostic information must be gathered and provided to IBM Support for troubleshooting the Cloud Pak for Integration instance?
Standard OpenShift Container Platform logs.
Platform Navigator event logs.
Cloud Pak For Integration activity logs.
Integration tracing activity reports.
When troubleshooting an IBM Cloud Pak for Integration (CP4I) v2021.2 instance, IBM Support requires diagnostic data that provides insights into the system’s performance, errors, and failures. The most critical diagnostic information comes from the Standard OpenShift Container Platform logs because:
CP4I runs on OpenShift, and its components are deployed as Kubernetes pods, meaning logs from OpenShift provide essential insights into infrastructure-level and application-level issues.
The OpenShift logs include:
Pod logs (oc logs
Event logs (oc get events), which provide details about errors, scheduling issues, or failed deployments.
Node and system logs, which help diagnose resource exhaustion, networking issues, or storage failures.
B. Platform Navigator event logs → Incorrect
While Platform Navigator manages CP4I services, its event logs focus mainly on UI-related issues and do not provide deep troubleshooting data needed for IBM Support.
C. Cloud Pak For Integration activity logs → Incorrect
CP4I activity logs include component-specific logs but do not cover the underlying OpenShift platform or container-level issues, which are crucial for troubleshooting.
D. Integration tracing activity reports → Incorrect
Integration tracing focuses on tracking API and message flows but is not sufficient for diagnosing broader CP4I system failures or deployment issues.
Explanation of Incorrect Answers:
IBM Cloud Pak for Integration Troubleshooting Guide
OpenShift Log Collection for Support
IBM MustGather for Cloud Pak for Integration
Red Hat OpenShift Logging and Monitoring
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What technology are OpenShift Pipelines based on?
Travis
Jenkins
Tekton
Argo CD
OpenShift Pipelines are based on Tekton, an open-source framework for building Continuous Integration/Continuous Deployment (CI/CD) pipelines natively in Kubernetes.
Tekton provides Kubernetes-native CI/CD functionality by defining pipeline resources as custom resources (CRDs) in OpenShift. This allows for scalable, cloud-native automation of software delivery.
Kubernetes-Native: Unlike Jenkins, which requires external servers or agents, Tekton runs natively in OpenShift/Kubernetes.
Serverless & Declarative: Pipelines are defined using YAML configurations, and execution is event-driven.
Reusable & Extensible: Developers can define Tasks, Pipelines, and Workspaces to create modular workflows.
Integration with GitOps: OpenShift Pipelines support Argo CD for GitOps-based deployment strategies.
Why Tekton is Used in OpenShift Pipelines?Example of a Tekton Pipeline Definition in OpenShift:apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: example-pipeline
spec:
tasks:
- name: echo-hello
taskSpec:
steps:
- name: echo
image: ubuntu
script: |
#!/bin/sh
echo "Hello, OpenShift Pipelines!"
A. Travis → ❌ Incorrect
Travis CI is a cloud-based CI/CD service primarily used for GitHub projects, but it is not used in OpenShift Pipelines.
B. Jenkins → ❌ Incorrect
OpenShift previously supported Jenkins-based CI/CD, but OpenShift Pipelines (Tekton) is now the recommended Kubernetes-native alternative.
Jenkins requires additional agents and servers, whereas Tekton runs serverless in OpenShift.
D. Argo CD → ❌ Incorrect
Argo CD is used for GitOps-based deployments, but it is not the underlying technology of OpenShift Pipelines.
Tekton and Argo CD can work together, but Argo CD alone does not handle CI/CD pipelines.
Explanation of Incorrect Answers:
IBM Cloud Pak for Integration CI/CD Pipelines
Red Hat OpenShift Pipelines (Tekton)
Tekton Pipelines Documentation
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
An administrator is looking to install Cloud Pak for Integration on an OpenShift cluster. What is the result of executing the following?
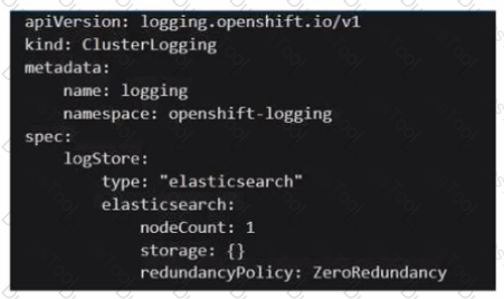
A single node ElasticSearch cluster with default persistent storage.
A single infrastructure node with persisted ElasticSearch.
A single node ElasticSearch cluster which auto scales when redundancyPolicy is set to MultiRedundancy.
A single node ElasticSearch cluster with no persistent storage.
The given YAML configuration is for ClusterLogging in an OpenShift environment, which is used for centralized logging. The key part of the specification that determines the behavior of Elasticsearch is:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 1
storage: {}
redundancyPolicy: ZeroRedundancy
nodeCount: 1
This means the Elasticsearch cluster will consist of only one node (single-node deployment).
storage: {}
The empty storage field implies no persistent storage is configured.
This means that if the pod is deleted or restarted, all stored logs will be lost.
redundancyPolicy: ZeroRedundancy
ZeroRedundancy means there is no data replication, making the system vulnerable to data loss if the pod crashes.
In contrast, a redundancy policy like MultiRedundancy ensures high availability by replicating data across multiple nodes, but that is not the case here.
Analysis of Key Fields:
Evaluating Answer Choices:Option
Explanation
Correct?
A. A single node ElasticSearch cluster with default persistent storage.
Incorrect, because storage: {} means no persistent storage is configured.
❌
B. A single infrastructure node with persisted ElasticSearch.
Incorrect, as this is not configuring an infrastructure node, and storage is not persistent.
❌
C. A single node ElasticSearch cluster which auto scales when redundancyPolicy is set to MultiRedundancy.
Incorrect, because setting MultiRedundancy does not automatically enable auto-scaling. Scaling needs manual intervention or Horizontal Pod Autoscaler (HPA).
❌
D. A single node ElasticSearch cluster with no persistent storage.
Correct, because nodeCount: 1 creates a single node, and storage: {} ensures no persistent storage.
✅
Final Answer:✅ D. A single node ElasticSearch cluster with no persistent storage.
IBM CP4I Logging and Monitoring Documentation
Red Hat OpenShift Logging Documentation
Elasticsearch Redundancy Policies in OpenShift Logging
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
If the App Connect Operator is installed in a restricted network, which statement is true?
Simple Storage Service (S3) can not be used for BAR files.
Ephemeral storage can not be used for BAR files.
Only Ephemeral storage is supported for BAR files.
Persistent Claim storage can not be used for BAR files.
In IBM Cloud Pak for Integration (CP4I) v2021.2, when App Connect Operator is deployed in a restricted network (air-gapped environment), access to external cloud-based services (such as AWS S3) is typically not available.
A restricted network means no direct internet access, so external storage services like Amazon S3 cannot be used to store Broker Archive (BAR) files.
BAR files contain packaged integration flows for IBM App Connect Enterprise (ACE).
In restricted environments, administrators must use internal storage options, such as:
Persistent Volume Claims (PVCs)
Ephemeral storage (temporary, in-memory storage)
Why Option A (S3 Cannot Be Used) is Correct:
B. Ephemeral storage cannot be used for BAR files. → Incorrect
Ephemeral storage is supported but is not recommended for production because data is lost when the pod restarts.
C. Only Ephemeral storage is supported for BAR files. → Incorrect
Both Ephemeral storage and Persistent Volume Claims (PVCs) are supported for storing BAR files.
Ephemeral storage is not the only option.
D. Persistent Claim storage cannot be used for BAR files. → Incorrect
Persistent Volume Claims (PVCs) are a supported and recommended method for storing BAR files in a restricted network.
This ensures that integration flows persist even if a pod is restarted or redeployed.
Explanation of Incorrect Answers:
IBM App Connect Enterprise - BAR File Storage Options
IBM Cloud Pak for Integration Storage Considerations
IBM Cloud Pak for Integration Deployment in Restricted Environments
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which two authentication types support single sign-on?
2FA
Enterprise LDAP
Plain text over HTTPS
Enterprise SSH
OpenShift authentication
Single Sign-On (SSO) is an authentication mechanism that allows users to log in once and gain access to multiple applications without re-entering credentials. In IBM Cloud Pak for Integration (CP4I), Enterprise LDAP and OpenShift authentication both support SSO.
Enterprise LDAP (B) – ✅ Supports SSO
Lightweight Directory Access Protocol (LDAP) is commonly used in enterprises for centralized authentication.
CP4I can integrate with Enterprise LDAP, allowing users to authenticate once and access multiple cloud services without needing separate logins.
OpenShift Authentication (E) – ✅ Supports SSO
OpenShift provides OAuth-based authentication, enabling SSO across multiple OpenShift-integrated services.
CP4I uses OpenShift’s built-in identity provider to allow seamless user authentication across different Cloud Pak components.
A. 2FA (Incorrect):
Two-Factor Authentication (2FA) enhances security by requiring an additional verification step but does not inherently support SSO.
C. Plain Text over HTTPS (Incorrect):
Plain text authentication is insecure and does not support SSO.
D. Enterprise SSH (Incorrect):
SSH authentication is used for remote access to servers but is not related to SSO.
Analysis of the Incorrect Options:
IBM Cloud Pak for Integration Authentication & SSO Guide
Red Hat OpenShift Authentication and Identity Providers
IBM Cloud Pak - Integrating with Enterprise LDAP
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which two Red Hat OpenShift Operators should be installed to enable OpenShift Logging?
OpenShift Console Operator
OpenShift Logging Operator
OpenShift Log Collector
OpenShift Centralized Logging Operator
OpenShift Elasticsearch Operator
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, logging is a critical component for monitoring cluster and application activities. To enable OpenShift Logging, two key operators must be installed:
OpenShift Logging Operator (B)
This operator is responsible for managing the logging stack in OpenShift.
It helps configure and deploy logging components like Fluentd, Kibana, and Elasticsearch within the OpenShift cluster.
It provides a unified way to collect and visualize logs across different workloads.
OpenShift Elasticsearch Operator (E)
This operator manages the Elasticsearch cluster, which is the central data store for log aggregation in OpenShift.
Elasticsearch stores logs collected from cluster nodes and applications, making them searchable and analyzable via Kibana.
Without this operator, OpenShift Logging cannot function, as it depends on Elasticsearch for log storage.
A. OpenShift Console Operator → Incorrect
The OpenShift Console Operator manages the web UI of OpenShift but has no role in logging.
It does not collect, store, or manage logs.
C. OpenShift Log Collector → Incorrect
There is no official OpenShift component or operator named "OpenShift Log Collector."
Log collection is handled by Fluentd, which is managed by the OpenShift Logging Operator.
D. OpenShift Centralized Logging Operator → Incorrect
This is not a valid OpenShift operator.
The correct operator for centralized logging is OpenShift Logging Operator.
Explanation of Incorrect Answers:
OpenShift Logging Overview
OpenShift Logging Operator Documentation
OpenShift Elasticsearch Operator Documentation
IBM Cloud Pak for Integration Logging Configuration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What is a prerequisite for setting a custom certificate when replacing the default ingress certificate?
The new certificate private key must be unencrypted.
The certificate file must have only a single certificate.
The new certificate private key must be encrypted.
The new certificate must be self-signed certificate.
When replacing the default ingress certificate in IBM Cloud Pak for Integration (CP4I) v2021.2, one critical requirement is that the private key associated with the new certificate must be unencrypted.
OpenShift’s Ingress Controller (which CP4I uses) requires an unencrypted private key to properly load and use the custom TLS certificate.
Encrypted private keys would require manual decryption each time the ingress controller starts, which is not supported for automation.
The custom certificate and its key are stored in a Kubernetes secret, which already provides encryption at rest, making additional encryption unnecessary.
Why Option A (Unencrypted Private Key) is Correct:To apply a new custom certificate for ingress, the process typically involves:
Creating a Kubernetes secret containing the unencrypted private key and certificate:
sh
CopyEdit
oc create secret tls custom-ingress-cert \
--cert=custom.crt \
--key=custom.key -n openshift-ingress
Updating the OpenShift Ingress Controller configuration to use the new secret.
B. The certificate file must have only a single certificate. → ❌ Incorrect
The certificate file can contain a certificate chain, including intermediate and root certificates, to ensure proper validation by clients.
It is not limited to a single certificate.
C. The new certificate private key must be encrypted. → ❌ Incorrect
If the private key is encrypted, OpenShift cannot automatically use it without requiring a decryption passphrase, which is not supported for automated deployments.
D. The new certificate must be a self-signed certificate. → ❌ Incorrect
While self-signed certificates can be used, they are not mandatory.
Administrators typically use certificates from trusted Certificate Authorities (CAs) to avoid browser security warnings.
Explanation of Incorrect Answers:
Replacing the default ingress certificate in OpenShift
IBM Cloud Pak for Integration Security Configuration
OpenShift Ingress TLS Certificate Management
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
The OpenShift Logging Operator monitors a particular Custom Resource (CR). What is the name of the Custom Resource used by the OpenShift Logging Opera-tor?
ClusterLogging
DefaultLogging
ElasticsearchLog
LoggingResource
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, logging is managed through the OpenShift Logging Operator. This operator is responsible for collecting, storing, and forwarding logs within the cluster.
The OpenShift Logging Operator monitors a specific Custom Resource (CR) named ClusterLogging, which defines the logging stack configuration.
The ClusterLogging CR is used to configure and manage the cluster-wide logging stack, including components like:
Fluentd (Log collection and forwarding)
Elasticsearch (Log storage and indexing)
Kibana (Log visualization)
Administrators define log collection, storage, and forwarding settings using this CR.
How the ClusterLogging Custom Resource Works:Example of a ClusterLogging CR Definition:apiVersion: logging.openshift.io/v1
kind: ClusterLogging
metadata:
name: instance
namespace: openshift-logging
spec:
managementState: Managed
logStore:
type: elasticsearch
retentionPolicy:
application:
maxAge: 7d
collection:
type: fluentd
This configuration sets up an Elasticsearch-based log store with Fluentd as the log collector.
The OpenShift Logging Operator monitors the ClusterLogging CR to manage logging settings.
It defines how logs are collected, stored, and forwarded across the cluster.
IBM Cloud Pak for Integration uses this CR when integrating OpenShift’s logging system.
Why Answer A (ClusterLogging) is Correct?
B. DefaultLogging → Incorrect
There is no such resource named DefaultLogging in OpenShift.
The correct resource is ClusterLogging.
C. ElasticsearchLog → Incorrect
Elasticsearch is the default log store, but it is managed within ClusterLogging, not as a separate CR.
D. LoggingResource → Incorrect
This is not an actual OpenShift CR related to logging.
Explanation of Incorrect Answers:
OpenShift Logging Overview
Configuring OpenShift Cluster Logging
IBM Cloud Pak for Integration - Logging and Monitoring
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What is one method that can be used to uninstall IBM Cloud Pak for Integra-tion?
Uninstall.sh
Cloud Pak for Integration console
Operator Catalog
OpenShift console
Uninstalling IBM Cloud Pak for Integration (CP4I) v2021.2 requires removing the operators, instances, and related resources from the OpenShift cluster. One method to achieve this is through the OpenShift console, which provides a graphical interface for managing operators and deployments.
The OpenShift Web Console allows administrators to:
Navigate to Operators → Installed Operators and remove CP4I-related operators.
Delete all associated custom resources (CRs) and namespaces where CP4I was deployed.
Ensure that all PVCs (Persistent Volume Claims) and secrets associated with CP4I are also deleted.
This is an officially supported method for uninstalling CP4I in OpenShift environments.
Why Option D (OpenShift Console) is Correct:
A. Uninstall.sh → ❌ Incorrect
There is no official Uninstall.sh script provided by IBM for CP4I removal.
IBM’s documentation recommends manual removal through OpenShift.
B. Cloud Pak for Integration console → ❌ Incorrect
The CP4I console is used for managing integration components but does not provide an option to uninstall CP4I itself.
C. Operator Catalog → ❌ Incorrect
The Operator Catalog lists available operators but does not handle uninstallation.
Operators need to be manually removed via the OpenShift Console or CLI.
Explanation of Incorrect Answers:
Uninstalling IBM Cloud Pak for Integration
OpenShift Web Console - Removing Installed Operators
Best Practices for Uninstalling Cloud Pak on OpenShift
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What is the result Of issuing the oc extract secret/platform—auth—idp—credentials --to=- command?
Writes the OpenShift Container Platform credentials to the current directory.
Generates Base64 decoded secrets for all Cloud Pak for Integration users.
Displays the credentials of the admin user.
Distributes credentials throughout the Cloud Pak for Integration platform.
The command:
oc extract secret/platform-auth-idp-credentials --to=-
is used to retrieve and display the admin user credentials stored in the platform-auth-idp-credentials secret within an OpenShift-based IBM Cloud Pak for Integration (CP4I) deployment.
In IBM Cloud Pak Foundational Services, the platform-auth-idp-credentials secret contains the admin username and password used to authenticate with OpenShift and Cloud Pak services.
The oc extract command decodes the secret and displays its contents in plaintext in the terminal.
The --to=- flag directs the output to standard output (STDOUT), ensuring that the credentials are immediately visible instead of being written to a file.
This command is commonly used for recovering lost admin credentials or retrieving them for automated processes.
Why Option C (Displays the credentials of the admin user) is Correct:
A. Writes the OpenShift Container Platform credentials to the current directory. → Incorrect
The --to=- option displays the credentials, but it does not write them to a file in the directory.
To save the credentials to a file, the command would need a filename, e.g., --to=admin-creds.txt.
B. Generates Base64 decoded secrets for all Cloud Pak for Integration users. → Incorrect
The command only extracts one specific secret (platform-auth-idp-credentials), which contains the admin credentials only.
It does not generate or decode secrets for all users.
D. Distributes credentials throughout the Cloud Pak for Integration platform. → Incorrect
The command extracts and displays credentials, but it does not distribute or propagate them.
Credentials distribution in Cloud Pak for Integration is handled through Identity and Access Management (IAM) configurations.
Explanation of Incorrect Answers:
IBM Cloud Pak Foundational Services - Retrieving Admin Credentials
OpenShift CLI (oc extract) Documentation
IBM Cloud Pak for Integration Identity and Access Management
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which two statements are true about the Ingress Controller certificate?
The administrator can specify a custom certificate at later time.
The Ingress Controller does not support the use of custom certificate.
By default. OpenShift uses an internal self-signed certificate.
By default. OpenShift does not use any certificate if one is not applied during the initial setup.
Certificate assignment is only applicable during initial setup.
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, the Ingress Controller is responsible for managing external access to services running within the cluster. The Ingress Controller certificate ensures secure communication between clients and the OpenShift cluster.
A. The administrator can specify a custom certificate at a later time. ✅
OpenShift allows administrators to replace the default self-signed certificate with a custom TLS certificate at any time.
This is typically done using a Secret in the appropriate namespace and updating the IngressController resource.
Example command to update the Ingress Controller certificate:
Explanation of Correct Answers:oc create secret tls my-custom-cert --cert=custom.crt --key=custom.key -n openshift-ingress
oc patch ingresscontroller default -n openshift-ingress-operator --type=merge -p '{"spec":{"defaultCertificate":{"name":"my-custom-cert"}}}'
This ensures secure access with a trusted certificate instead of the default self-signed certificate.
C. By default, OpenShift uses an internal self-signed certificate. ✅
If no custom certificate is provided, OpenShift automatically generates and assigns a self-signed certificate for the Ingress Controller.
This certificate is not trusted by browsers or external clients and typically causes SSL/TLS warnings unless replaced.
B. The Ingress Controller does not support the use of a custom certificate. ❌ Incorrect
OpenShift fully supports custom certificates for the Ingress Controller, allowing secure TLS communication.
D. By default, OpenShift does not use any certificate if one is not applied during the initial setup. ❌ Incorrect
OpenShift always generates a default self-signed certificate if no custom certificate is provided.
E. Certificate assignment is only applicable during initial setup. ❌ Incorrect
Custom certificates can be assigned at any time, not just during initial setup.
Explanation of Incorrect Answers:
OpenShift Ingress Controller TLS Configuration
IBM Cloud Pak for Integration Security Configuration
Managing OpenShift Cluster Certificates
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What ate two ways to add the IBM Cloud Pak tor Integration CatalogSource ob-jects to an OpenShift cluster that has access to the internet?
Copy the resource definition code into a file and use the oc apply -f filename command line option.
Import the catalog project from https://ibm.github.eom/icr-io/cp4int:2.4
Deploy the catalog the Red Hat OpenShift Application Runtimes.
Download the Cloud Pak for Integration driver from partnercentral.ibm.com to a local machine and deploy using the oc new-project command line option
Paste the resource definition code into the import YAML dialog of the OpenShift Admin web console and click Create.
To add the IBM Cloud Pak for Integration (CP4I) CatalogSource objects to an OpenShift cluster that has internet access, there are two primary methods:
Using oc apply -f filename (Option A)
The CatalogSource resource definition can be written in a YAML file and applied using the OpenShift CLI.
This method ensures that the cluster is correctly set up with the required catalog sources for CP4I.
Example command:
sh
CopyEdit
oc apply -f cp4i-catalogsource.yaml
This is a widely used approach for configuring OpenShift resources.
Using the OpenShift Admin Web Console (Option E)
Administrators can manually paste the CatalogSource YAML definition into the OpenShift Admin Web Console.
Navigate to Administrator → Operators → OperatorHub → Create CatalogSource, paste the YAML, and click Create.
This provides a UI-based alternative to using the CLI.
B (Incorrect): There is no valid icr-io/cp4int:2.4 catalog project import method for adding a CatalogSource. IBM’s container images are hosted on IBM Cloud Container Registry (ICR), but this method is not used for adding a CatalogSource.
C (Incorrect): Red Hat OpenShift Application Runtimes (RHOAR) is unrelated to the CatalogSource object creation for CP4I.
D (Incorrect): Downloading the CP4I driver and using oc new-project is not the correct approach for adding a CatalogSource. The oc new-project command is used to create OpenShift projects but does not deploy catalog sources.
Explanation of Incorrect Options:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Documentation: Managing Operator Lifecycle with OperatorHub
OpenShift Docs: Creating a CatalogSource
IBM Knowledge Center: Installing IBM Cloud Pak for Integration
Given the high availability requirements for a Cloud Pak for Integration deployment, which two components require a quorum for high availability?
Multi-instance Queue Manager
API Management (API Connect)
Application Integration (App Connect)
Event Gateway Service
Automation Assets
In IBM Cloud Pak for Integration (CP4I) v2021.2, ensuring high availability (HA) requires certain components to maintain a quorum. A quorum is a mechanism where a majority of nodes or instances must agree on a state to prevent split-brain scenarios and ensure consistency.
IBM MQ Multi-instance Queue Manager is designed for high availability.
It runs in an active-standby configuration where a shared storage is required, and a quorum ensures that failover occurs correctly.
If the primary queue manager fails, quorum logic ensures that another instance assumes control without data corruption.
API Connect operates in a distributed cluster architecture where multiple components (such as the API Manager, Analytics, and Gateway) work together.
A quorum is required to ensure consistency and avoid conflicts in API configurations across multiple instances.
API Connect uses MongoDB as its backend database, and MongoDB requires a replica set quorum for high availability and failover.
Why "Multi-instance Queue Manager" (A) Requires a Quorum?Why "API Management (API Connect)" (B) Requires a Quorum?
Why Not the Other Options?Option
Reason for Exclusion
C. Application Integration (App Connect)
While App Connect can be deployed in HA mode, it does not require a quorum. It uses Kubernetes scaling and load balancing instead.
D. Event Gateway Service
Event Gateway is stateless and relies on horizontal scaling rather than quorum-based HA.
E. Automation Assets
This component stores automation-related assets but does not require quorum for HA. It typically relies on persistent storage replication.
Thus, Multi-instance Queue Manager (IBM MQ) and API Management (API Connect) require quorum to ensure high availability in Cloud Pak for Integration.
IBM MQ Multi-instance Queue Manager HA
IBM API Connect High Availability and Quorum
CP4I High Availability Architecture
MongoDB Replica Set Quorum in API Connect
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which of the following would contain mqsc commands for queue definitions to be executed when new MQ containers are deployed?
MORegistry
CCDTJSON
Operatorlmage
ConfigMap
In IBM Cloud Pak for Integration (CP4I) v2021.2, when deploying IBM MQ containers in OpenShift, queue definitions and other MQSC (MQ Script Command) commands need to be provided to configure the MQ environment dynamically. This is typically done using a Kubernetes ConfigMap, which allows administrators to define and inject configuration files, including MQSC scripts, into the containerized MQ instance at runtime.
A ConfigMap in OpenShift or Kubernetes is used to store configuration data as key-value pairs or files.
For IBM MQ, a ConfigMap can include an MQSC script that contains queue definitions, channel settings, and other MQ configurations.
When a new MQ container is deployed, the ConfigMap is mounted into the container, and the MQSC commands are executed to set up the queues.
Why is ConfigMap the Correct Answer?Example Usage:A sample ConfigMap containing MQSC commands for queue definitions may look like this:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-mq-config
data:
10-create-queues.mqsc: |
DEFINE QLOCAL('MY.QUEUE') REPLACE
DEFINE QLOCAL('ANOTHER.QUEUE') REPLACE
This ConfigMap can then be referenced in the MQ Queue Manager’s deployment configuration to ensure that the queue definitions are automatically executed when the MQ container starts.
A. MORegistry - Incorrect
The MORegistry is not a component used for queue definitions. Instead, it relates to Managed Objects in certain IBM middleware configurations.
B. CCDTJSON - Incorrect
CCDTJSON refers to Client Channel Definition Table (CCDT) in JSON format, which is used for defining MQ client connections rather than queue definitions.
C. OperatorImage - Incorrect
The OperatorImage contains the IBM MQ Operator, which manages the lifecycle of MQ instances in OpenShift, but it does not store queue definitions or execute MQSC commands.
IBM Documentation: Configuring IBM MQ with ConfigMaps
IBM MQ Knowledge Center: Using MQSC commands in Kubernetes ConfigMaps
IBM Redbooks: IBM Cloud Pak for Integration Deployment Guide
Analysis of Other Options:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which statement is true regarding an upgrade of App Connect Operators?
The App Connect Operator can be upgraded automatically when a new compatible version is available.
The setting for automatic upgrades can only be specified at the time the App Connect Operator is installed.
Once the App Connect Operator is installed the approval strategy cannot be modified.
There is no option to require manual approval for updating the App Connect Operator.
In IBM Cloud Pak for Integration (CP4I), operators—including the App Connect Operator—are managed through Operator Lifecycle Manager (OLM) in Red Hat OpenShift. OLM provides two upgrade approval strategies:
Automatic: The operator is upgraded as soon as a new compatible version becomes available.
Manual: An administrator must manually approve the upgrade.
The App Connect Operator supports automatic upgrades when configured with the Automatic approval strategy during installation or later through OperatorHub settings. If this setting is enabled, OpenShift will detect new compatible versions and upgrade the operator without requiring manual intervention.
B. The setting for automatic upgrades can only be specified at the time the App Connect Operator is installed.
Incorrect, because the approval strategy can be modified later in OpenShift’s OperatorHub or via CLI.
C. Once the App Connect Operator is installed, the approval strategy cannot be modified.
Incorrect, because OpenShift allows administrators to change the approval strategy at any time after installation.
D. There is no option to require manual approval for updating the App Connect Operator.
Incorrect, because OLM provides both manual and automatic approval options. If manual approval is set, the administrator must manually approve each upgrade.
Why Other Options Are Incorrect:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM App Connect Operator Upgrade Process
OpenShift Operator Lifecycle Manager (OLM) Documentation
IBM Cloud Pak for Integration Operator Management
An administrator is using the Storage Suite for Cloud Paks entitlement that they received with their Cloud Pak for Integration (CP4I) licenses. The administrator has 200 VPC of CP4I and wants to be licensed to use 8TB of OpenShift Container Storage for 3 years. They have not used or allocated any of their Storage Suite entitlement so far.
What actions must be taken with their Storage Suite entitlement?
The Storage Suite entitlement covers the administrator's license needs only if the OpenShift cluster is running on IBM Cloud or AWS.
The Storage Suite entitlement can be used for OCS. however 8TB will require 320 VPCs of CP41
The Storage Suite entitlement already covers the administrator's license needs.
The Storage Suite entitlement only covers IBM Spectrum Scale, Spectrum Virtualize. Spectrum Discover, and Spectrum Protect Plus products, but the licenses can be converted to OCS.
The IBM Storage Suite for Cloud Paks provides storage licensing for various IBM Cloud Pak solutions, including Cloud Pak for Integration (CP4I). It supports multiple storage options, such as IBM Spectrum Scale, IBM Spectrum Virtualize, IBM Spectrum Discover, IBM Spectrum Protect Plus, and OpenShift Container Storage (OCS).
IBM licenses CP4I based on Virtual Processor Cores (VPCs).
Storage Suite for Cloud Paks uses a conversion factor:
1 VPC of CP4I provides 25GB of OCS storage entitlement.
To calculate how much CP4I VPC is required for 8TB (8000GB) of OCS:
Understanding Licensing Conversion:8000GB25GB per VPC=320 VPCs\frac{8000GB}{25GB \text{ per VPC}} = 320 \text{ VPCs}25GB per VPC8000GB=320 VPCs
Since the administrator only has 200 VPCs of CP4I, they do not have enough entitlement to cover the full 8TB of OCS storage. They would need an additional 120 VPCs to fully meet the requirement.
A. The Storage Suite entitlement covers the administrator's license needs only if the OpenShift cluster is running on IBM Cloud or AWS.
Incorrect, because Storage Suite for Cloud Paks can be used on any OpenShift deployment, including on-premises, IBM Cloud, AWS, or other cloud providers.
C. The Storage Suite entitlement already covers the administrator's license needs.
Incorrect, because 200 VPCs of CP4I only provide 5TB (200 × 25GB) of OCS storage, but the administrator needs 8TB.
D. The Storage Suite entitlement only covers IBM Spectrum products, but the licenses can be converted to OCS.
Incorrect, because Storage Suite already includes OpenShift Container Storage (OCS) as part of its licensing model without requiring any conversion.
Why Other Options Are Incorrect:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Storage Suite for Cloud Paks Licensing Guide
IBM Cloud Pak for Integration Licensing Information
OpenShift Container Storage Entitlement

TESTED 26 Apr 2025
Copyright © 2014-2025 DumpsTool. All Rights Reserved