You are a developer at a large organization. Your team uses Git for source code management (SCM). You want to ensure that your team follows Google-recommended best practices to manage code to drive higher rates of software delivery. Which SCM process should your team use?
You recently developed a new application. You want to deploy the application on Cloud Run without a Dockerfile. Your organization requires that all container images are pushed to a centrally managed container repository. How should you build your container using Google Cloud services? (Choose two.)
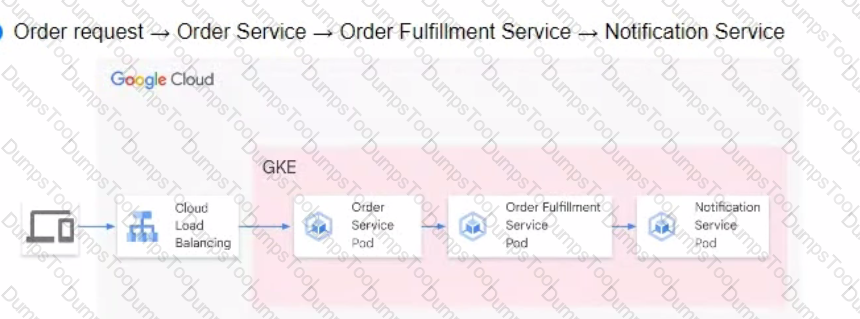
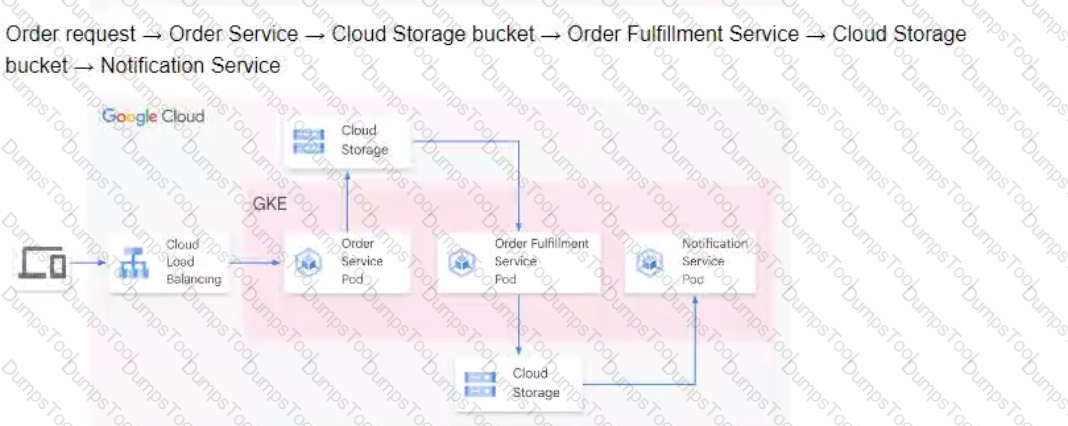
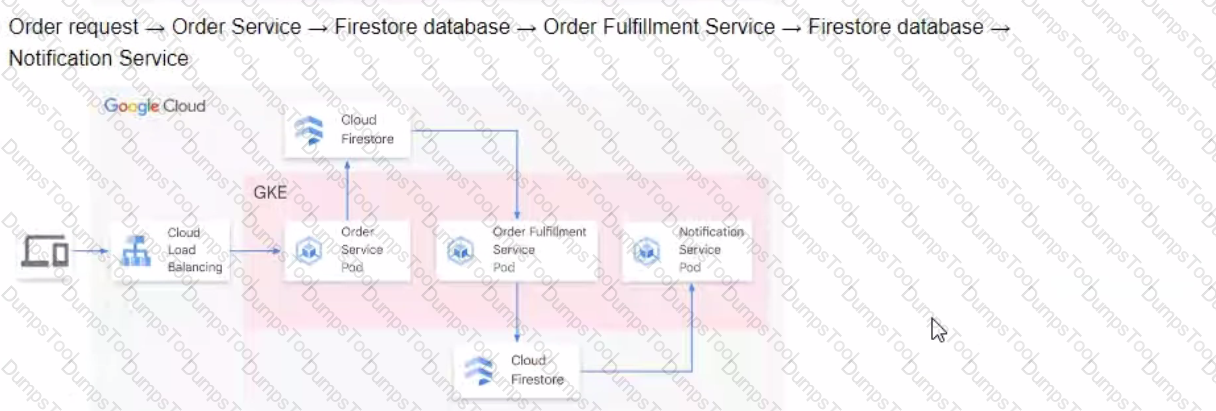
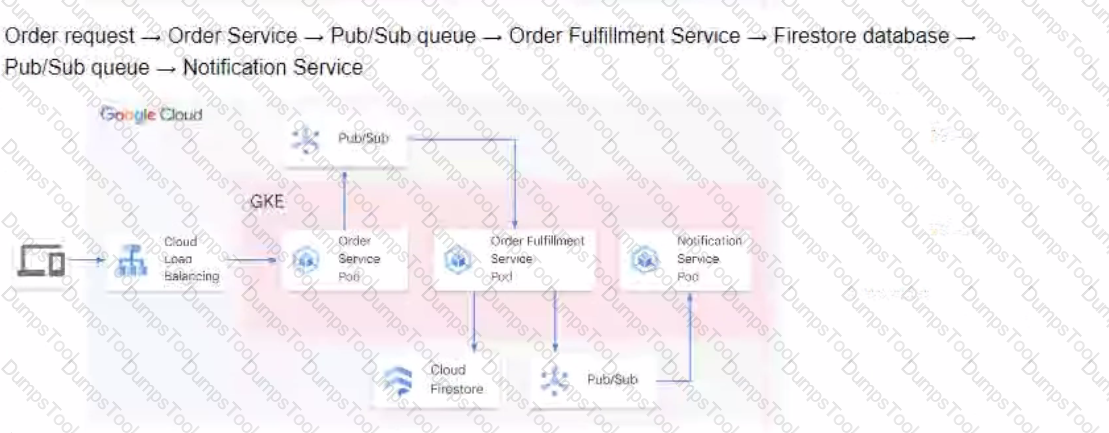
You are developing a flower ordering application Currently you have three microservices.
• Order Service (receives the orders).
• Order Fulfillment Service (processes the orders).
• Notification Service (notifies the customer when the order is filled).
You need to determine how the services will communicate with each other. You want incoming orders to be processed quickly and you need to collect order information for fulfillment. You also want to make sure orders are not lost between your services and are able to communicate asynchronously. How should the requests be processed?
You have an application deployed in Google Kubernetes Engine (GKE). You need to update the application to make authorized requests to Google Cloud managed services. You want this to be a one-time setup, and you need to follow security best practices of auto-rotating your security keys and storing them in an encrypted store. You already created a service account with appropriate access to the Google Cloud service. What should you do next?
You support an application that uses the Cloud Storage API. You review the logs and discover multiple HTTP 503 Service Unavailable error responses from the API. Your application logs the error and does not take any further action. You want to implement Google-recommended retry logic to improve success rates. Which approach should you take?
You have a mixture of packaged and internally developed applications hosted on a Compute Engine instance that is running Linux. These applications write log records as text in local files. You want the logs to be written to Cloud Logging. What should you do?
You are a developer at a social media company The company runs their social media website on-premises and uses MySQL as a backend to store user profiles and user posts. Your company plans to migrate to Google Cloud, and your team will migrate user profile information to Firestore. You are tasked with designing the Firestore collections. What should you do?
You manage a microservice-based ecommerce platform on Google Cloud that sends confirmation emails to a third-party email service provider using a Cloud Function. Your company just launched a marketing campaign, and some customers are reporting that they have not received order confirmation emails. You discover that the services triggering the Cloud Function are receiving HTTP 500 errors. You need to change the way emails are handled to minimize email loss. What should you do?
Your application is logging to Stackdriver. You want to get the count of all requests on all /api/alpha/*
endpoints.
What should you do?
You have deployed a Java application to Cloud Run. Your application requires access to a database hosted on Cloud SQL Due to regulatory requirements: your connection to the Cloud SQL instance must use its internal IP address. How should you configure the connectivity while following Google-recommended best practices'?
You recently joined a new team that has a Cloud Spanner database instance running in production. Your manager has asked you to optimize the Spanner instance to reduce cost while maintaining high reliability and availability of the database. What should you do?
You are building a mobile application that will store hierarchical data structures in a database. The application will enable users working offline to sync changes when they are back online. A backend service will enrich the data in the database using a service account. The application is expected to be very popular and needs to scale seamlessly and securely. Which database and IAM role should you use?
You are in the final stage of migrating an on-premises data center to Google Cloud. You are quickly approaching your deadline, and discover that a web API is running on a server slated for decommissioning. You need to recommend a solution to modernize this API while migrating to Google Cloud. The modernized web API must meet the following requirements:
• Autoscales during high traffic periods at the end of each month
• Written in Python 3.x
• Developers must be able to rapidly deploy new versions in response to frequent code changes
You want to minimize cost, effort, and operational overhead of this migration. What should you do?
You manage your company's ecommerce platform's payment system, which runs on Google Cloud. Your company must retain user logs for 1 year for internal auditing purposes and for 3 years to meet compliance requirements. You need to store new user logs on Google Cloud to minimize on-premises storage usage and ensure that they are easily searchable. You want to minimize effort while ensuring that the logs are stored correctly. What should you do?
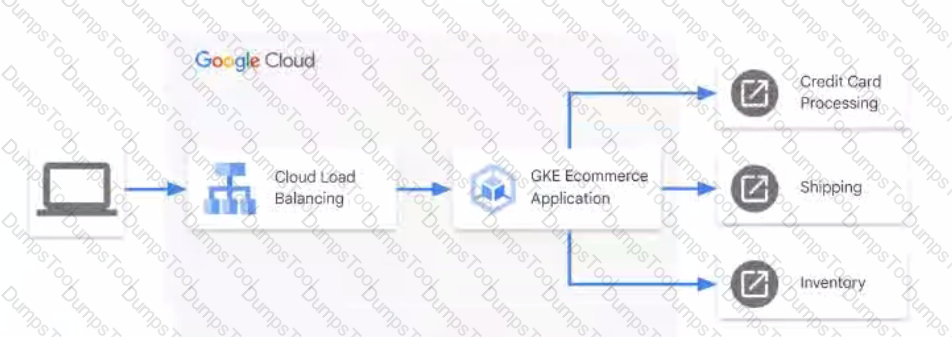
You have an ecommerce application hosted in Google Kubernetes Engine (GKE) that receives external requests and forwards them to third-party APIs external to Google Cloud. The third-party APIs are responsible for credit card processing, shipping, and inventory management using the process shown in the diagram.
Your customers are reporting that the ecommerce application is running slowly at unpredictable times. The application doesn't report any metrics You need to determine the cause of the inconsistent performance What should you do?
You are working on a new application that is deployed on Cloud Run and uses Cloud Functions Each time new features are added, new Cloud Functions and Cloud Run services are deployed You use ENV variables to keep track of the services and enable interservice communication but the maintenance of the ENV variables has become difficult. You want to implement dynamic discovery in a scalable way. What should you do?
The new version of your containerized application has been tested and is ready to deploy to production on Google Kubernetes Engine. You were not able to fully load-test the new version in pre-production environments, and you need to make sure that it does not have performance problems once deployed. Your deployment must be automated. What should you do?
Your application requires service accounts to be authenticated to GCP products via credentials stored on its host Compute Engine virtual machine instances. You want to distribute these credentials to the host instances as securely as possible. What should you do?
You have an application deployed in Google Kubernetes Engine (GKE) that reads and processes Pub/Sub messages. Each Pod handles a fixed number of messages per minute. The rate at which messages are published to the Pub/Sub topic varies considerably throughout the day and week, including occasional large batches of messages published at a single moment.
You want to scale your GKE Deployment to be able to process messages in a timely manner. What GKE feature should you use to automatically adapt your workload?
Your organization has recently begun an initiative to replatform their legacy applications onto Google Kubernetes Engine. You need to decompose a monolithic application into microservices. Multiple instances have read and write access to a configuration file, which is stored on a shared file system. You want to minimize the effort required to manage this transition, and you want to avoid rewriting the application code. What should you do?
You are developing a microservice-based application that will run on Google Kubernetes Engine (GKE). Some of the services need to access different Google Cloud APIs. How should you set up authentication of these services in the cluster following Google-recommended best practices? (Choose two.)
You developed a JavaScript web application that needs to access Google Drive’s API and obtain permission from users to store files in their Google Drives. You need to select an authorization approach for your application. What should you do?
You are planning to deploy your application in a Google Kubernetes Engine (GKE) cluster. Your application
can scale horizontally, and each instance of your application needs to have a stable network identity and its
own persistent disk.
Which GKE object should you use?
You are using Cloud Build for your CI/CD pipeline to complete several tasks, including copying certain files to Compute Engine virtual machines. Your pipeline requires a flat file that is generated in one builder in the pipeline to be accessible by subsequent builders in the same pipeline. How should you store the file so that all the builders in the pipeline can access it?
You are developing a single-player mobile game backend that has unpredictable traffic patterns as users interact with the game throughout the day and night. You want to optimize costs by ensuring that you have enough resources to handle requests, but minimize over-provisioning. You also want the system to handle traffic spikes efficiently. Which compute platform should you use?
You need to containerize a web application that will be hosted on Google Cloud behind a global load balancer with SSL certificates. You don't have the time to develop authentication at the application level, and you want to offload SSL encryption and management from your application. You want to configure the architecture using managed services where possible What should you do?
Your security team is auditing all deployed applications running in Google Kubernetes Engine. After completing the audit, your team discovers that some of the applications send traffic within the cluster in clear text. You need to ensure that all application traffic is encrypted as quickly as possible while minimizing changes to your applications and maintaining support from Google. What should you do?
You are reviewing and updating your Cloud Build steps to adhere to Google-recommended practices. Currently, your build steps include:
1. Pull the source code from a source repository.
2. Build a container image
3. Upload the built image to Artifact Registry.
You need to add a step to perform a vulnerability scan of the built container image, and you want the results of the scan to be available to your deployment pipeline running in Google Cloud. You want to minimize changes that could disrupt other teams' processes What should you do?
You recently deployed a Go application on Google Kubernetes Engine (GKE). The operations team has noticed that the application's CPU usage is high even when there is low production traffic. The operations team has asked you to optimize your application's CPU resource consumption. You want to determine which Go functions consume the largest amount of CPU. What should you do?
You have an HTTP Cloud Function that is called via POST. Each submission’s request body has a flat, unnested JSON structure containing numeric and text data. After the Cloud Function completes, the collected data should be immediately available for ongoing and complex analytics by many users in parallel. How should you persist the submissions?
Your team develops services that run on Google Cloud. You need to build a data processing service and will use Cloud Functions. The data to be processed by the function is sensitive. You need to ensure that invocations can only happen from authorized services and follow Google-recommended best practices for securing functions. What should you do?
Your development team has been tasked with maintaining a .NET legacy application. The application incurs occasional changes and was recently updated. Your goal is to ensure that the application provides consistent results while moving through the CI/CD pipeline from environment to environment. You want to minimize the cost of deployment while making sure that external factors and dependencies between hosting environments are not problematic. Containers are not yet approved in your organization. What should you do?
You want to notify on-call engineers about a service degradation in production while minimizing development
time.
What should you do?
Your company’s corporate policy states that there must be a copyright comment at the very beginning of all source files. You want to write a custom step in Cloud Build that is triggered by each source commit. You need the trigger to validate that the source contains a copyright and add one for subsequent steps if not there. What should you do?
You are a developer at a large corporation You manage three Google Kubernetes Engine clusters. Your team’s developers need to switch from one cluster to another regularly without losing access to their preferred development tools. You want to configure access to these clusters using the fewest number of steps while following Google-recommended best practices. What should you do?
HipLocal wants to reduce the number of on-call engineers and eliminate manual scaling.
Which two services should they choose? (Choose two.)
In order to meet their business requirements, how should HipLocal store their application state?
For this question, refer to the HipLocal case study.
Which Google Cloud product addresses HipLocal’s business requirements for service level indicators and objectives?
For this question, refer to the HipLocal case study.
HipLocal is expanding into new locations. They must capture additional data each time the application is launched in a new European country. This is causing delays in the development process due to constant schema changes and a lack of environments for conducting testing on the application changes. How should they resolve the issue while meeting the business requirements?
For this question, refer to the HipLocal case study.
HipLocal's application uses Cloud Client Libraries to interact with Google Cloud. HipLocal needs to configure authentication and authorization in the Cloud Client Libraries to implement least privileged access for the application. What should they do?
HipLocal has connected their Hadoop infrastructure to GCP using Cloud Interconnect in order to query data stored on persistent disks.
Which IP strategy should they use?
In order for HipLocal to store application state and meet their stated business requirements, which database service should they migrate to?
HipLocal’s data science team wants to analyze user reviews.
How should they prepare the data?
For this question, refer to the HipLocal case study.
A recent security audit discovers that HipLocal’s database credentials for their Compute Engine-hosted MySQL databases are stored in plain text on persistent disks. HipLocal needs to reduce the risk of these credentials being stolen. What should they do?
HipLocal wants to improve the resilience of their MySQL deployment, while also meeting their business and technical requirements.
Which configuration should they choose?
For this question, refer to the HipLocal case study.
How should HipLocal redesign their architecture to ensure that the application scales to support a large increase in users?
HipLocal's APIs are showing occasional failures, but they cannot find a pattern. They want to collect some
metrics to help them troubleshoot.
What should they do?
For this question refer to the HipLocal case study.
HipLocal wants to reduce the latency of their services for users in global locations. They have created read replicas of their database in locations where their users reside and configured their service to read traffic using those replicas. How should they further reduce latency for all database interactions with the least amount of effort?
For this question, refer to the HipLocal case study.
How should HipLocal increase their API development speed while continuing to provide the QA team with a stable testing environment that meets feature requirements?
HipLocal's.net-based auth service fails under intermittent load.
What should they do?
HipLocal is configuring their access controls.
Which firewall configuration should they implement?

TESTED 23 Apr 2026