A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
A machine learning engineer is trying to scale a machine learning pipeline by distributing its single-node model tuning process. After broadcasting the entire training data onto each core, each core in the cluster can train one model at a time. Because the tuning process is still running slowly, the engineer wants to increase the level of parallelism from 4 cores to 8 cores to speed up the tuning process. Unfortunately, the total memory in the cluster cannot be increased.
In which of the following scenarios will increasing the level of parallelism from 4 to 8 speed up the tuning process?
An organization is developing a feature repository and is electing to one-hot encode all categorical feature variables. A data scientist suggests that the categorical feature variables should not be one-hot encoded within the feature repository.
Which of the following explanations justifies this suggestion?
A data scientist has produced three new models for a single machine learning problem. In the past, the solution used just one model. All four models have nearly the same prediction latency, but a machine learning engineer suggests that the new solution will be less time efficient during inference.
In which situation will the machine learning engineer be correct?
A data scientist is wanting to explore summary statistics for Spark DataFrame spark_df. The data scientist wants to see the count, mean, standard deviation, minimum, maximum, and interquartile range (IQR) for each numerical feature.
Which of the following lines of code can the data scientist run to accomplish the task?
A data scientist is utilizing MLflow Autologging to automatically track their machine learning experiments. After completing a series of runs for the experiment experiment_id, the data scientist wants to identify the run_id of the run with the best root-mean-square error (RMSE).
Which of the following lines of code can be used to identify the run_id of the run with the best RMSE in experiment_id?
A)

B)

C)
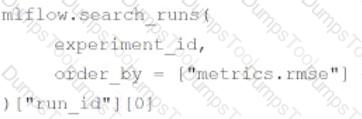
D)

A machine learning engineer has created a Feature Table new_table using Feature Store Client fs. When creating the table, they specified a metadata description with key information about the Feature Table. They now want to retrieve that metadata programmatically.
Which of the following lines of code will return the metadata description?
A data scientist has defined a Pandas UDF function predict to parallelize the inference process for a single-node model:

They have written the following incomplete code block to use predict to score each record of Spark DataFramespark_df:

Which of the following lines of code can be used to complete the code block to successfully complete the task?
A data scientist has produced two models for a single machine learning problem. One of the models performs well when one of the features has a value of less than 5, and the other model performs well when the value of that feature is greater than or equal to 5. The data scientist decides to combine the two models into a single machine learning solution.
Which of the following terms is used to describe this combination of models?
Which of the following approaches can be used to view the notebook that was run to create an MLflow run?
A data scientist wants to use Spark ML to impute missing values in their PySpark DataFrame features_df. They want to replace missing values in all numeric columns in features_df with each respective numeric column’s median value.
They have developed the following code block to accomplish this task:

The code block is not accomplishing the task.
Which reasons describes why the code block is not accomplishing the imputation task?
A data scientist has developed a random forest regressor rfr and included it as the final stage in a Spark MLPipeline pipeline. They then set up a cross-validation process with pipeline as the estimator in the following code block:

Which of the following is a negative consequence of includingpipelineas the estimator in the cross-validation process rather thanrfras the estimator?
A machine learning engineer is using the following code block to scale the inference of a single-node model on a Spark DataFrame with one million records:

Assuming the default Spark configuration is in place, which of the following is a benefit of using anIterator?
A machine learning engineer wants to parallelize the training of group-specific models using the Pandas Function API. They have developed thetrain_modelfunction, and they want to apply it to each group of DataFramedf.
They have written the following incomplete code block:

Which of the following pieces of code can be used to fill in the above blank to complete the task?
A data scientist has written a feature engineering notebook that utilizes the pandas library. As the size of the data processed by the notebook increases, the notebook's runtime is drastically increasing, but it is processing slowly as the size of the data included in the process increases.
Which of the following tools can the data scientist use to spend the least amount of time refactoring their notebook to scale with big data?
A data scientist is using MLflow to track their machine learning experiment. As a part of each of their MLflow runs, they are performing hyperparameter tuning. The data scientist would like to have one parent run for the tuning process with a child run for each unique combination of hyperparameter values. All parent and child runs are being manually started with mlflow.start_run.
Which of the following approaches can the data scientist use to accomplish this MLflow run organization?

TESTED 23 Jan 2025